 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMStyle Benchmark: Evaluating Text Style Transfer for Chatbots
Mar 13, 2024



Since the breakthrough of ChatGPT, large language models (LLMs) have garnered significant attention in the research community. With the development of LLMs, the question of text style transfer for conversational models has emerged as a natural extension, where chatbots may possess their own styles or even characters. However, standard evaluation metrics have not yet been established for this new settings. This paper aims to address this issue by proposing the LMStyle Benchmark, a novel evaluation framework applicable to chat-style text style transfer (C-TST), that can measure the quality of style transfer for LLMs in an automated and scalable manner. In addition to conventional style strength metrics, LMStyle Benchmark further considers a novel aspect of metrics called appropriateness, a high-level metrics take account of coherence, fluency and other implicit factors without the aid of reference samples. Our experiments demonstrate that the new evaluation methods introduced by LMStyle Benchmark have a higher correlation with human judgments in terms of appropriateness. Based on LMStyle Benchmark, we present a comprehensive list of evaluation results for popular LLMs, including LLaMA, Alpaca, and Vicuna, reflecting their stylistic properties, such as formality and sentiment strength, along with their appropriateness.
ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT
Nov 30, 2022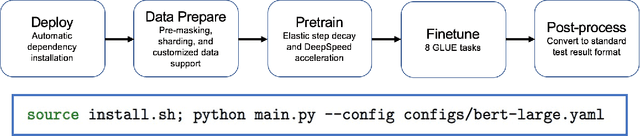
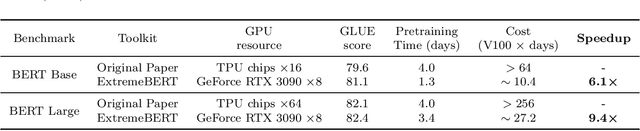

In this paper, we present ExtremeBERT, a toolkit for accelerating and customizing BERT pretraining. Our goal is to provide an easy-to-use BERT pretraining toolkit for the research community and industry. Thus, the pretraining of popular language models on customized datasets is affordable with limited resources. Experiments show that, to achieve the same or better GLUE scores, the time cost of our toolkit is over $6\times$ times less for BERT Base and $9\times$ times less for BERT Large when compared with the original BERT paper. The documentation and code are released at https://github.com/extreme-bert/extreme-bert under the Apache-2.0 license.